Différencier un vélo d’un tyrannosaure dans un film (2017)


On vous a récemment parlé du “Machine Learning”, ou apprentissage automatique, comme étant l’une des 7 tendances majeures de l’année en technologie. Voici l’une de ses applications pratiques les plus fascinantes qu’on ait vues dernièrement !
Lors de la récente conférence Cloud Next qui a eu lieu à San Francisco, Google a dévoilé un nouvel outil qui sera sans doute fort utile pour les entreprises produisant un volume important de vidéos. Le géant a en effet présenté une API d’analyse de contenu vidéo, utilisable sur les fichiers stockés dans le Google Cloud Storage. Elle permet d’associer automatiquement une taxonomie riche à une vidéo, ce qui rend ainsi le contenu de la vidéo accessible aux moteurs de recherche conventionnels.
Plusieurs outils de reconnaissance d’images existent à l’heure actuelle : on n’a qu’à penser à la reconnaissance des visages, proposée dans différentes applications de gestion de photothèque par exemple. Mais la particularité de l’outil de Google est d’offrir l’analyse automatique de n’importe quelle vidéo numérique. Jusqu’a récemment, les vidéos étaient entièrement tributaires des métadonnées associées à la main par des humains pour être trouvables. Qui n’a jamais pesté pour trouver une vidéo mal indexée sur YouTube, par exemple, parce que les mots-clés nécessaires n’étaient pas présents et qu’un fichier vidéo n’est qu’une grosse masse indéchiffrable d’octets pour un outil de recherche par essence textuel… La reconnaissance de la piste audio est déjà un progrès dans la voie de la compréhension d’une vidéo par les machines, celle des images animées est l’étape ultime.
Comment ça fonctionne
L’outil, appelé pour l’instant Cloud Video Intelligence, est pour le moment disponible en mode “bêta privée” et bien sûr, réservé aux clients de la plateforme infonuagique de Google.
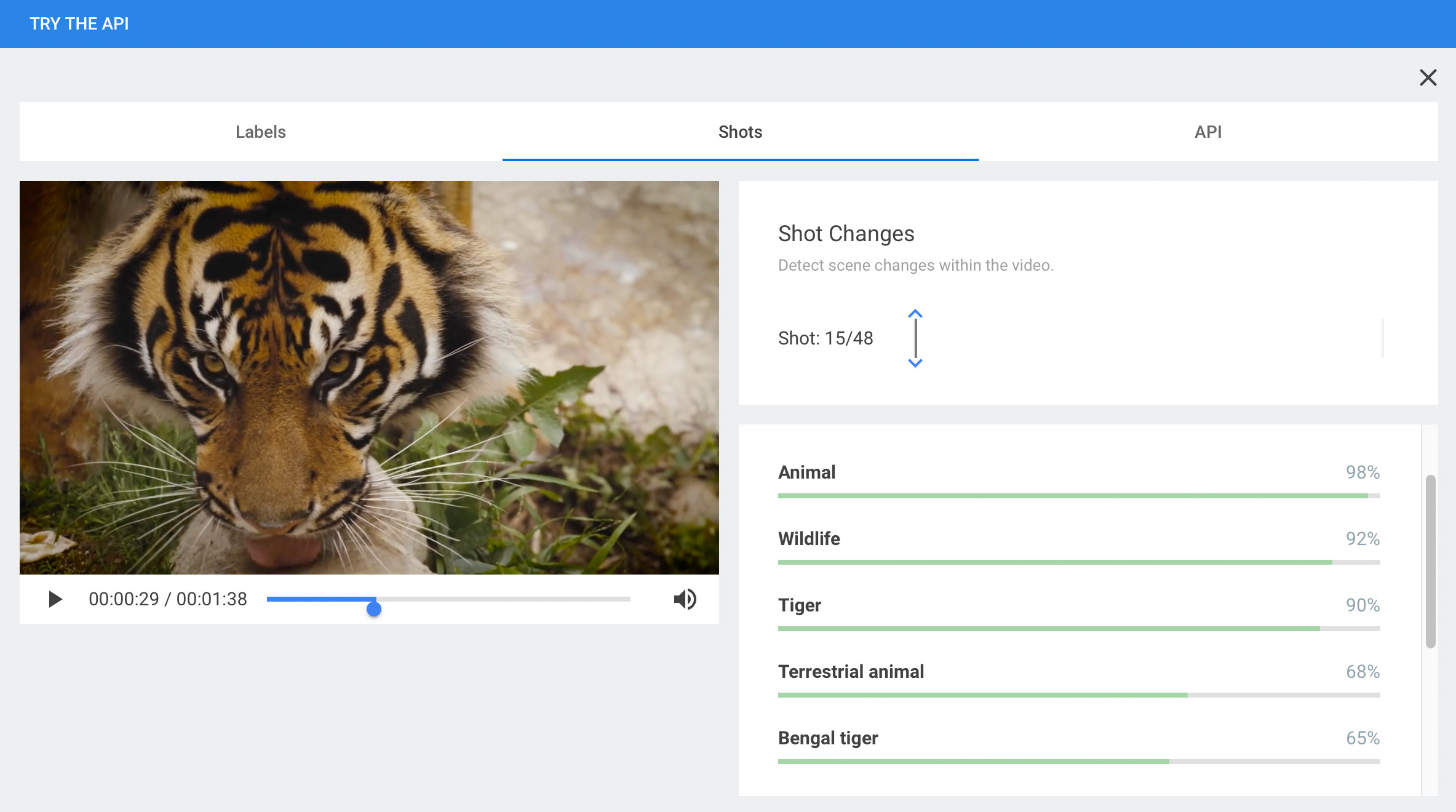
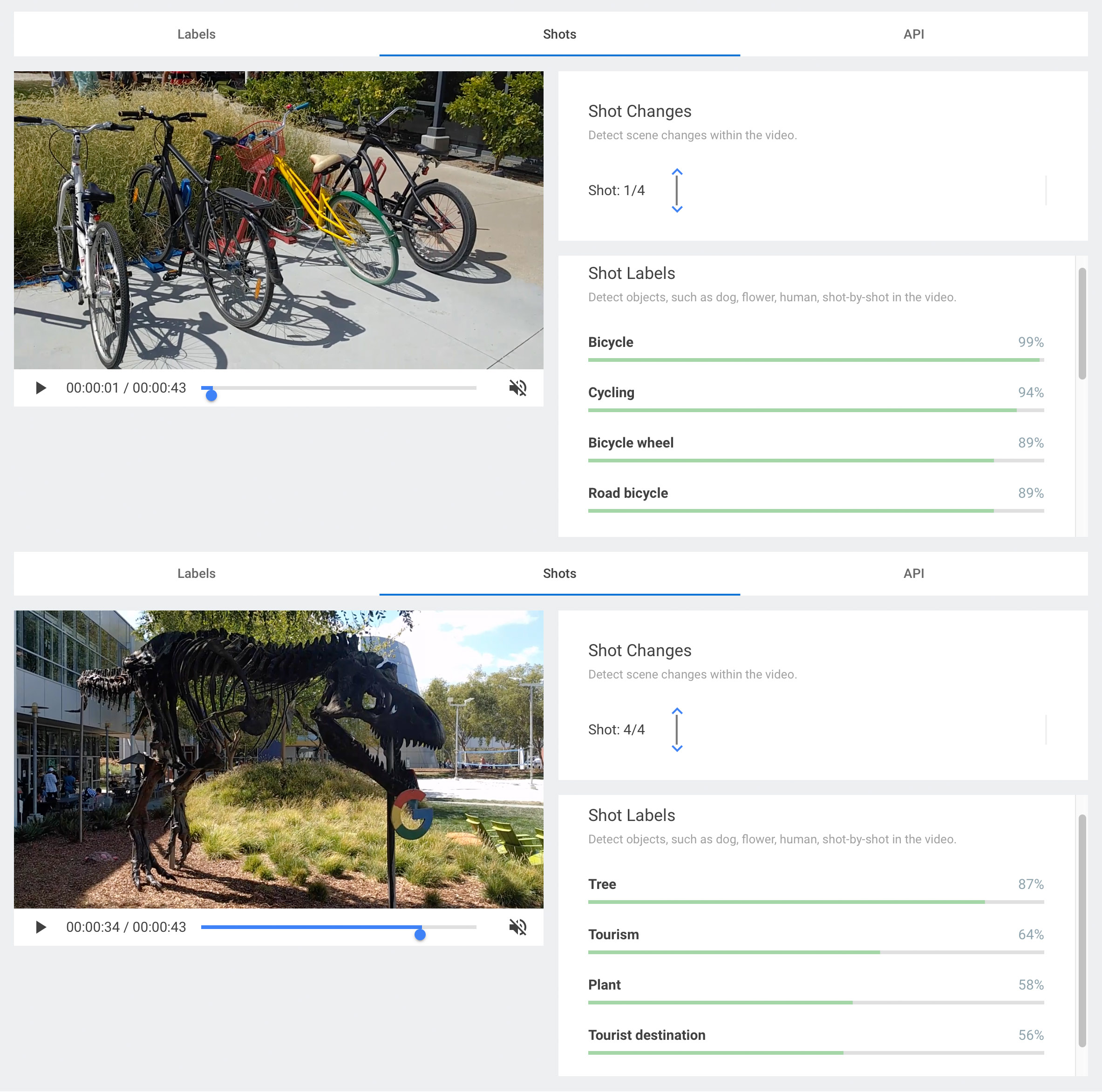
L’API a pour but d’identifier des lieux et des objets précis, ou encore des êtres humains ou des animaux à partir de n’importe quel contenu vidéo. Une fois l’identification faite, un catalogage des contenus peut s’effectuer grâce aux mots-clés proposés par l’API, chaque mot-clé étant associé à un degré de certitude.
Si l’API est relativement certaine qu’il s’agit bien : primo, d’un animal, secundo, d’un tigre, et que, tertio, ce tigre est probablement du Bengale ; elle notera en pourcentage le degré de précision pour chaque déduction. Et comme l’analyse repose sur l’engin d’apprentissage automatique de Google, la précision deviendra de plus en plus importante au fur et à mesure que le logiciel sera exposé à davantage de contenu.
Les premiers essais ne donnent pas des résultats particulièrement précis pour l’instant, mais tout cela fait partie de la stratégie de Google, qui préfère toujours prendre la place le plus rapidement possible. Le mantra interne du géant de Mountain View est en effet “Launch and Iterate”, lancer un produit en l’état, l’améliorer par itérations. Une stratégie que l’on pourrait décrire comme suit si nous étions railleurs : lancez votre application au grand jour, même truffée de bogues et aux fonctionnalités incomplètes, laissez vos clients faire le travail de découverte de ces bogues, s’excuser platement en cas de plaintes, réparer, publier une nouvelle version, puis, recommencez, encore et encore.
De nombreuses applications possibles
On peut facilement imaginer que des médias qui sont souvent aux prises avec d’importantes archives d’images animées, pourront enfin cataloguer leurs contenus automatiquement, avec plus d’efficacité, de précision et de manière bien plus économique. Un exemple parmi tant d’autres : si une équipe de production documentaire cherche des extraits contenant une voiture Ford modèle T, l’outil permettra de trouver dans une banque d’archives toutes les séquences où cette automobile peut être aperçue, même s’il ne s’agit pas du sujet principal d’une vidéo.
La force de l’API est qu’elle propose une couche d’analyse contextuelle, grâce à l’intelligence artificielle, qui fait en sorte que le contenu est reconnu dans son contexte. Ce n’est donc pas une simple reconnaissance d’images isolées les unes des autres, mais l’analyse d’un continuum d’images ; ce qui permet ainsi de reconnaître les changements de scène et de cadrage. À l’avenir, le système pourrait aussi reconnaître les scènes clés dans un enregistrement, par exemple, identifier tous les plans correspondants à des essais, des coups francs, des buts, etc., dans l’enregistrement d’une retransmission de match de rugby.
Une autre application envisagée est l’exploitation en direct des flux provenant des caméras de surveillance. Sans opérateurs humains, le système pourra détecter et alerter en fonction de certains comportements prédéterminés : déplacement d’objet, chute d’un passant, automobile mal garée, etc.
En cette ère où les médias doivent se réinventer, la possibilité de bien maîtriser les contenus d’archives offre d’intéressantes nouvelles possibilités de monétisation de contenus existants. Le catalogage et la recherche, deux processus fastidieux aujourd’hui, pourront grâce à l’automatisation permettre une bien meilleure gestion des contenus.
How to tell a bike from a Tyrannosaurus Rex
In a recent blog post, we mentioned Machine Learning as one of this year’s 7 biggest technological trends. Here is one of the more fascinating applications of machine learning we’ve seen lately.
At its Cloud Next 2017 Conference in San Francisco, Google unveiled a godsend to companies that produce large amounts of video content. The Redwood Giant demonstrated a video content analysis API that can be used on files stored in Google Cloud Storage. The API automatically associates a rich taxonomy to videos, making the content of the videos searchable with conventional search engines.
Image recognition tools already exist, such as the facial recognition tools available in various photo management applications. But what’s special about the Google tool is that it automatically analyzes any digital video. Until recently, videos were only searchable with the metadata associated to them manually by human beings, since videos are nothing more than an undecipherable mass of bits for text-based search tools. Yet who hasn’t cursed while searching for a poorly indexed video on YouTube (for example) because the keywords were wrong or missing? The advent of audio recognition was a step forward in the machine learning process; video recognition is the final step.
How it works
Google’s tool, temporarily called Cloud Video Intelligence, is currently only available in private beta mode to paying clients of Google’s Cloud platform.
The API seeks to identify specific objects, places, human beings or animals, in any video content. Identified items are catalogued under keywords suggested by the API, each keyword having a certainty score.
For example, say the API is reasonably certain that it has found an animal, probably a tiger, possibly a Bengal tiger. Each deduction has an associated percentage of certainty. And since the analysis is performed by Google’s automatic learning tool, accuracy will improve as the application is exposed to more and more content.
Early trials are not particularly accurate, but this is normal for Google, whose strategy is to take the field as quickly as possible. Their mantra, after all, is “Launch and Iterate”, i.e. launch first, improve later. Cynics would say their strategy is rather to launch any old buggy, incomplete application as is, saddle customers with the work of finding the bugs, apologize, fix, launch a new version, repeat.
Many potential applications
Media companies that often deal with masses of archived animations will finally be able to catalogue their content automatically, more efficiently, accurately and cheaply. Say a documentary company is looking for clips containing a Ford Model T. The tool can run through an archived database and extract all sequences featuring this particular car, even if only incidentally.
The greatest strength of the API is to apply a layer of contextual analysis thanks to artificial intelligence, enabling the content to be recognized in context. So it’s not just recognizing images in isolation; it’s analyzing a continuum of images, which means that the API picks up scene and frame changes. In future, the system will be able to recognize key scenes in a recording, for example, all shots related to the various tries, free kicks, goals, etc., in a rugby match.
Another potential application would be in the field of live surveillance-camera footage. For example, a system would be able to automatically detect issues and raise the alarm based on predetermined data, such as a particular object moving, a pedestrian falling, an illegally-parked car, etc.
In this era of new media, the survival of traditional media may depend on their ability to mine their archives and find interesting new ways to repackage existing content. Content management could be greatly enhanced thanks to the automation of cataloguing and searching, two processes that are currently highly labour-intensive.